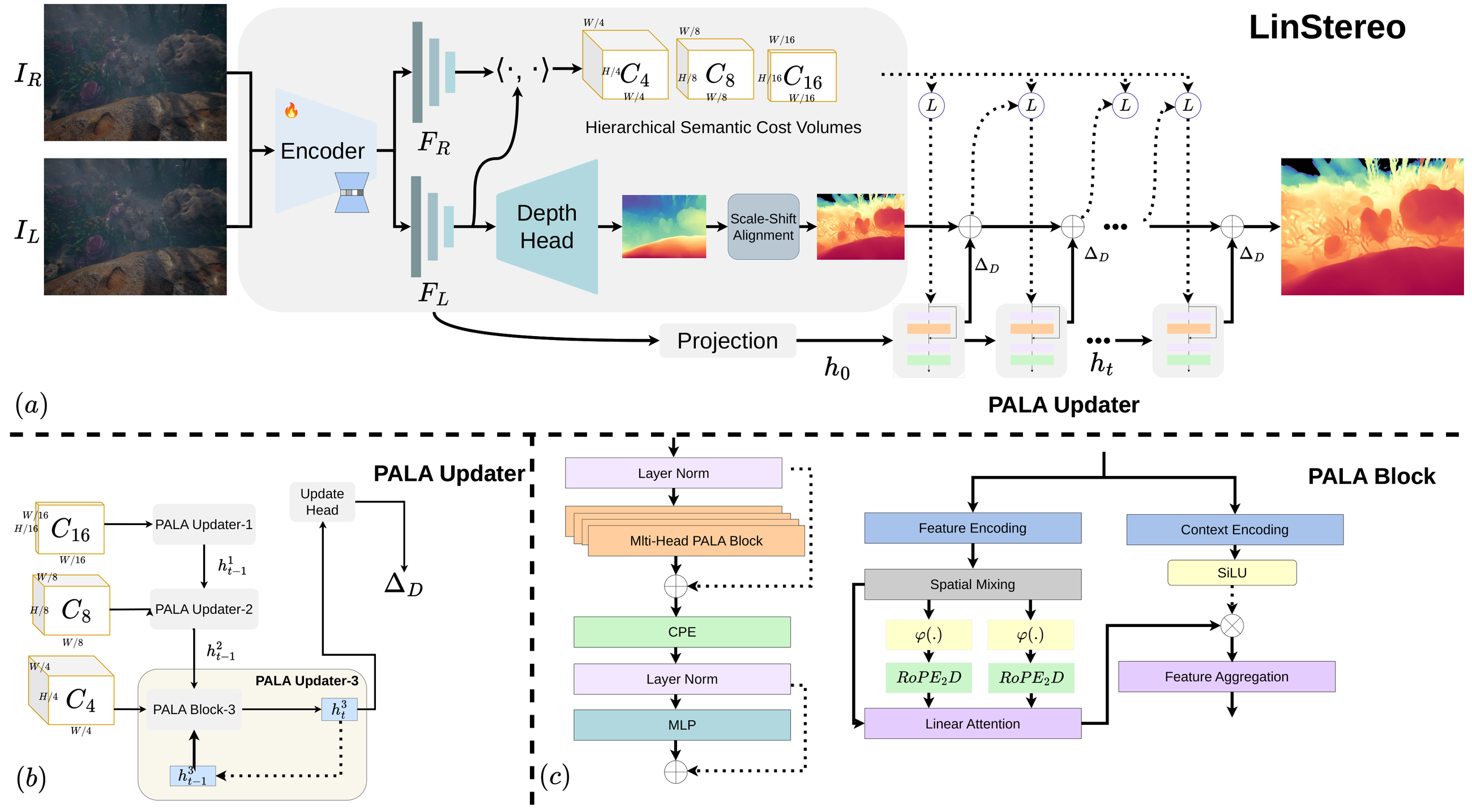
Position-Aware Linear Attention (PALA)
Standard linear attention reaches O(N) by precomputing KᵀV and sharing it across queries — but that collapses all spatial relationships into one global summary, making attention position-agnostic. PALA restores spatial structure with 2D rotary position encoding applied asymmetrically: only the numerator is position-augmented, while the denominator keeps the plain kernels for stable normalization.
A local spatial encoding on the value branch and an adaptive gate let each location absorb new evidence where matching is confident and preserve its estimate where it is not — so reliable disparity gradually fills uncertain regions. Cost stays O(N·C²); one PALA iteration is as cheap as a ConvGRU step (3.50 ms vs 3.63 ms).